반응형
dplyr 패키지 (group_by, summarize, arrange)
group_by 및 summarize : 그룹화된 데이터에서 요약 통계량을 계산
group_by() 및 summarize() 함수는 dplyr 패키지의 중요한 기능 중 하나로, 데이터 프레임을 그룹화하고 각 그룹에 대한 요약 통계량을 계산하는 데 사용된다.
| summarize() 내 통계량 | 사용 함수 및 내용 |
| 평균 (Mean) | mean(x): 열 x의 평균 값을 계산 |
| 중앙값 (Median) | median(x) : 열 x의 중앙값을 계산 |
| 최댓값 (Maximum) | max(x) 열 x에서 최댓값을 계산 |
| 최솟값 (Minimum) | min(x): 열 x에서 최솟값을 계산 |
| 범위 (Range) | max(x) - min(x): 열 x의 범위를 계산 |
| 표준편차 (Standard Deviation): | sd(x): 열 x의 표준편차를 계산 |
| 분산 (Variance) | var(x): 열 x의 분산을 계산 |
| 합계 (Sum) | sum(x): 열 x의 합계를 계산 |
| 개수 (Count) | n(): 그룹 내 행의 개수를 계산 |
| 사분위수 (Quantiles) | quantile(x, probs): 열 x에서 주어진 확률에 해당하는 사분위수를 계산 |
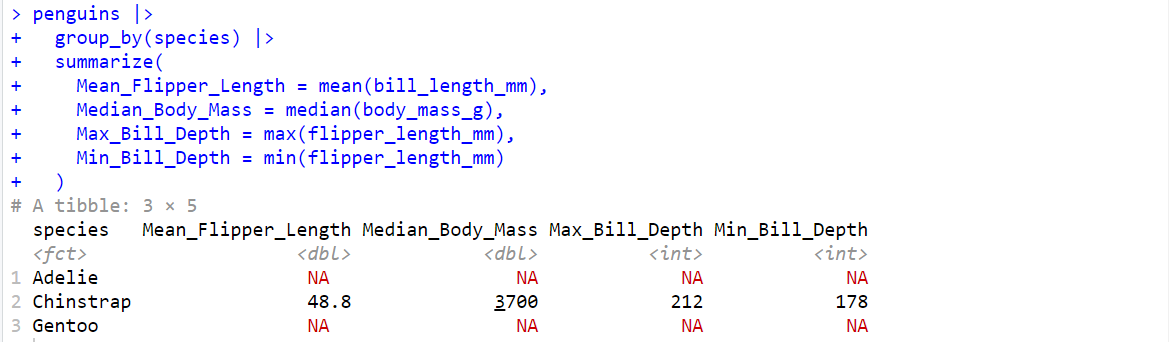
| # Species (펭귄 종류)에 따라 그룹화하고 그룹화된 데이터에서 요약 통계량 계산 penguins |> group_by(species) |> summarize( Mean_Flipper_Length = mean(bill_length_mm), Median_Body_Mass = median(body_mass_g), Max_Bill_Depth = max(flipper_length_mm), Min_Bill_Depth = min(flipper_length_mm) ) |
| #그룹 내 행의 개수(count) 계산 penguins |> group_by(species) |> summarize( Count = n() ) |

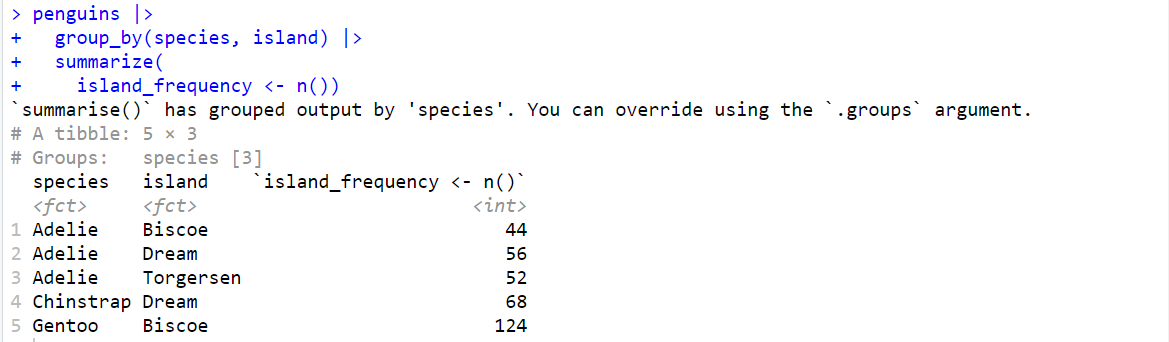
| #Island 열의 빈도수 계산 penguins |> group_by(species, island) |> summarize( island_frequency <- n()) ) |
na.rm = TRUE 옵션
na.rm = TRUE 옵션을 사용하여 NA 값을 제외하고 요약 통계량을 계산한다.
(NA 값을 포함한 데이터에 대한 요약 통계량이 계산된다.)
| #na.rm = TRUE 옵션 사용 penguins |> group_by(species) |> summarize( Mean_Flipper_Length = mean(bill_length_mm, na.rm = TRUE), Median_Body_Mass = median(body_mass_g, na.rm = TRUE), Max_Bill_Depth = max(flipper_length_mm, na.rm = TRUE), Min_Bill_Depth = min(flipper_length_mm, na.rm = TRUE) ) |

n_distinct()
n_distinct() 함수를 사용하여 열의 고유한 값의 개수를 계산할 수 있다.
| #species (펭귄 종류) 열의 고유한 값의 개수 계산 penguins |> group_by(species) |> summarize( Unique_Species_Count = n_distinct(species) ) |

300x250
arrange : 데이터를 정렬
오름차순 (기본 옵션)
기본 정렬 방식이며 열의 값을 작은 값부터 큰 값으로 정렬
| penguins |> arrange(flipper_length_mm) |

내림차순 : desc()
내림차순은 열의 값을 큰 값부터 작은 값으로 정렬합니다. desc() 함수를 사용하여 내림차순 정렬을 지정
| penguins |> arrange(desc(flipper_length_mm)) |

desc() 함수를 ' - '로 대체할 수도 있다.
| penguins |> arrange( -(flipper_length_mm)) |

여러 열(변수)로 정렬
열(변수)을 여러 개 지정하면 첫 번째 열을 기준으로 정렬하고 동일한 값들에 대해서만 다음 열로 정렬한다.
| penguins |> arrange(species, sex, body_mass_g) |

| penguins |> arrange(species, desc(sex), body_mass_g) |

filter + group_by + summarize + arrange
filter(), mutate(), summarize(), arrange() 함수를 모두 사용하는 예제
| penguins |> mutate (body_mass_kg = body_mass_g/1000) |> filter (body_mass_kg >= 3.5) |> group_by(species) |> summarise( no_of_penguins = n() ) |> arrange(-no_of_penguins ) |

Pixabay로부터 입수된 Gerd Altmann님의 이미지 입니다.
728x90
'데이터 분석 (with Rstudio)' 카테고리의 다른 글
| [Rstudio] ggplot과 grammer of graphics (0) | 2023.10.10 |
|---|---|
| [Rstudio] 데이터 유형별 그래프 선택 기준 및 R 그래프 함수 (0) | 2023.10.09 |
| [Rstudio tidyverse] dplyr 패키지 (filter, select, mutate) (1) | 2023.10.07 |
| [R studio] tidyverse 패키지와 특장점 (1) | 2023.10.07 |
| [R studio] 다른 디렉터리 (디렉토리, 폴더) 파일 불러오기 저장하기 (0) | 2023.10.07 |



