
https://product.kyobobook.co.kr/detail/S000212170349
 |
데이터 분석에 대해서 쉽게 이해할 수 있는 책 작가들이 NEC(일본 전기 주식회사)의 회사원들이다. 간결한 문체와 다양한 예제를 통해서 이해하기 쉽게 설명하고 있다. 데이터 분석에 입문하는 회사원이나 학생들에게 추천한다. 총 7장으로 구성되어 있으며, 1장은 데이터 리터러시에 대해서 설명하고 있고, 7장은 전체 내용을 정리하고 있다. 2장에서 6장은 저자가 얘기하는 데이터 리터러시 관련 6가지 힘 (데이터를 읽는 힘, 데이터를 해석하는 힘, 데이터를 다루는 힘, 데이터를 분류하는 힘, 데이터에서 법칙을 발견하는 힘, 데이터를 보고 예측하는 힘) 중에서 데이터를 다루는 힘을 제외하고 순서대로 설명하고 있다. 즉, 이 책은 데이터를 다루는 방법이나 기술보다는 데이터를 읽고 파악하는 것에 중점을 두고 있다. |
[ 책 '데이터 과학자의 가설 사고' Overview 📘 ]
발행(출시)일자 : 2024년 02월 08일
쪽수 : 272쪽
역자 : 김지윤 (데이터 사이언스를 포함한 다양한 학문에 관심이 있는 번역가)
프로그래밍 용어를 사용하지 않고,
데이터 과학자의 사고를 배운다
이 책은 복잡한 계산, 엑셀, 프로그래밍 언어를 사용하지 않고,
종이와 연필만으로 데이터 과학자의 사고를 알려줍니다.
데이너 기본 개념을 쉽게 이해하고, 40개의 퀴즈를 풀면서
과학자의 사고 과정을 직접 체험해 보시기 바랍니다.
(책 후면 표지 내용 중)
[ 저자 소개 (책 내용) ]
[ 고추 다이스케 (孝忠 大輔, Kochu Daisuke) ]
일본 전기 주식회사(日本電気株式会社 Nippon Electric Company, Limited, NEC ) AI애널리틱스 사업통괄부 수석 데이터 과학자
2003년 4월 일본 전기 주식회사 입사, 유통-서비스업을 중심으로 분석 컨설팅을 제시하였고, 2010년 NEC 프로페셔널 인정 제도 '시니어 데이터 애널리스트' 초대 인정자가 되었다. 2018년 NEC 그릅의 AI인재 육성을 통괄하는 AI인재 육성 센터의 센터장으로 취임하여 AI인재 육성에 힘썼다. 2019년 AI인재를 육성하기 위한 NEC 아카데미 for AI를 개설해 학장을 지냈다. 저서로는 "AI 인재를 기르는 방법", "교양으로서의 데이터 과학", "데이터 과학장 검정 공식 레퍼런스북"이 있다.
NEC DX Innovators 100 인터뷰 : 03. 고추 다이스케 (孝忠 大輔)
https://jpn.nec.com/dx/special/interview/03.html
03.孝忠 大輔 | DX Innovators 100 インタビュー | DX with NEC: デジタルトランスフォーメーション | NEC
ビジネス×テクノロジーでDXを実現するNECのスペシャリスト集団「NEC DX Innovators 100」の特別インタビュー。第3回目は AI人材育成の第一人者 孝忠大輔にフォーカス。
jpn.nec.com
AI 인재육성의 중요성?
기술의 진화뿐만 아니라
그것을 사회에 전달할 수있는
"사람"이야말로 중요하다.
최첨단 AI 환경 "Sand Box"란?
누구나 최신의 AI에 접할 수 있는
환경을 만든다.
실제 경험에서 배우는
새로운 아이디어와 비즈니스를 낳는다.
요구되는 세 가지 기술?
데이터를 다룰 뿐만 아니라,
비즈니스에 빠뜨릴 수 있는 힘도 중요하다.
원동력은 데이터에 의한 가치 발견을
즐길 수 있는 마인드.
[ 가와치 아키오 (川地 章夫, Kawachi Akio) ]
일본 전기 주식회사 AI애널리틱스 사업통괄부 리드 데이터 과학자
2009년 4월 일본 전기 주식회사 입사, 통신 사업자를 위한 SE로 활동하다가 2015년 10월부터 데이터 과학자로 활동하기 시작했다. 지금까지 유통, 제조, 전력, 부동산, 관공서 등 폭넓은 업계에서 분석에 종사했다. 현재는 주로 분석을 제안하거나 인재를 육성하며 분석 어드바이저로 일한다.
[ 고노 슌스케 (河野 俊輔, Kono Shunsuke) ]
일본 전기 주식회사 AI애널리틱스 사업통괄부 리드 데이터 과학자
2014년 4월 일본 전기 주식회사 입사, 업무 개선을 위한 과제, 요건 분석 기술 연구 개발에 종사하다가 철도, 제조 영역의 고객을 중심으로 데이터 분석 프로젝트에 관여하고 있다. 분석 검증부터 적용까지 폭넓은 단계를 담당한다. 또, 고객 기업의 데이터 분석팀 설립과 육성 지원도 하고 있다.
[ 스즈키 가이리 (鈴木 海理, Suzuki Kairi) ]
일본 전기 주식회사 AI애널리틱스 사업통괄부 리드 데이터 과학자
2020년 4월 일본 전기 주식회사 입사, 데이터 과학자로서 데이터 분석 업무와 기술 검증 업무에 종사. 현재는 주로 관공서의 고객 데이터 분석 지원에 관여하고 있으며 요건 정의와 분석 검증, 적용을 담당한다.
[ 나가키 사키 (長城 沙樹, Nagaki Saki) ]
일본 전기 주식회사 AI애널리틱스 사업통괄부 리드 데이터 과학자
2018년 4월 일본 전기 주식회사 입사, 입사 이래로 데이터 과학자로서 여러 업계의 AI기술을 활용한 데이터 분석 업무에 종사하였고, 현재는 제조업, 에너지업, 철도업 고객을 중심으로 한 AI활용 안건 제안부터 고객 데이터를 이용한 검증, AI를 활용한 시스템 제안, AI 인재 육성 지원 등 폭넓게 활동하고 있다. 일본 데이터베이스 학회 회원이다.
[ 나카노 준이치 (中野 淳一, Nakano Junichi) ]
일본 전기 주식회사 AI애널리틱스 사업통괄부 리드 데이터 과학자
2007년 4월 일본 전기 주식회사 입사, 데이터웨어 하우스 시스템 설계, 개발, 보수 경험을 거쳐서 데이터 과학자로서 CRM 영역의 데이터 해석을 담당하고 있다. 현재는 NEC의 AU사업 확대에 공헌하는 한편, 데이터 분석을 이용한 Well-Being 향상 연구 등에도 몰두하고 있다. 2022년 3월 게이오대학 대학원 경영 관리 연구과 수료, 경영학 석사를 취득하였다.
[ 책 '데이터 과학자의 가설 사고' 주요 문구 📗 ]
[ 들어가며 (2022년 3월 저자를 대표해서, 고추 다이스케) ]
앞으로 디지털 사회를 살아가기 위해 직장인은 데이터를 읽는 힘, 데이터를 이해하는 힘, 데이터를 다루는 힘, 데이터를 분류하는 힘, 데이터에서 법칙을 발견하는 힘, 데이터를 보고 예측하는 힘이라는 6가지 힘(데이터 리터러시)을 몸에 익혀야 합니다.
[ 제1장 디지털 시대에 필요한 데이터 리터러시 ]
[ 1-1 디지털 시대의 도래 ]
(책의 Society 5.0 내용을 직접 일본 내각부 홈페이지에서 확인함)
Society 5.0이란? [일본 내각부 홈페이지(https://www8.cao.go.jp/cstp/society5_0/index.html]
우리나라가 목표로 해야 할 미래사회의 모습이며, 사냥사회(Society 1.0), 농경사회(Society 2.0), 공업사회(Society 3.0), 정보사회(Society 4.0)에 이은 새로운 사회입니다. 제5기 과학기술 기본계획(2016년 1월 22일 각의 결정)에 있어서, 「사이버 공간과 피지컬 공간을 고도로 융합시킨 시스템에 의해, 경제 발전과 사회적 과제의 해결을 양립하는 인간 중심의 사회 "로 Society 5.0이 처음으로 제창되었습니다.립하는 인간 중심의 사회 "로 Society 5.0이 처음으로 제창되었습니다.


[ 1-2 데이터 리터러시는 미래의 직장인에게 필수 스킬 / 1-3 데이터 리터러시를 익히자 ]
데이터 리터러시는 디지털 시대의 '읽기-쓰기-셈하기' 같은 소양

대량의 데이터에서 비즈니스에 도움이 되는 포인트를 골라내려면 데이터를 몇 가지 그룹으로 분류하고, 데이터 안에 숨어 있는 법칙을 찾는 힘이 필요합니다.
편의점 매출 데이터를 예로 생각해보면 날씨가 맑을 때의 데이터가 있는가 하면, 비 오늘 날의 데이터도 있습니다. 또, 도심의 오피스빌딩 안에 자리한 점포 데이터가 있는가 하면, 교회의 길가에 자리한 점포 데이터도 있습니다. 이런 데이터를 똑같이 취급하면 비즈니스에 도움이 되는 지식을 골라낼 수 없습니다. 이럴 때는 매출 데이터를 몇 가지 비슷한 그룹으로 분류하면 그룹별 특징을 파악할 수 있게 됩니다.
[ 제2장 데이터를 읽는 힘을 기른다 ]
데이터를 읽는 목적이나 데이터 뒤에 있는 배경을 생각하면서 데이터와 마주합니다.
데이터의 전체 경향을 파악할 때, 대푯값으로 판단하지 않고, 반드시 데이터 분포나 내역을 확인합니다.
복수의 데이터를 조합하면서 상관관계나 인과관계를 탐색합니다.
'평균값의 바탕이 된 데이터는 어떤 분포를 보이는가? 극단적으로 치우친 데이터에서 계산한 평균값은 아닌가?'를 의식하는 것이 중요합니다.
2-1 생각하면서 데이터를 읽자!
데이터를 파악할 때 데이터를 읽는 목적과 데이터에 있는 배경을 생각합니다.
그래프를 이용해서 데이터의 특징이나 경향 차이를 판단합니다.
2-2 전체의 경향을 파악하자
데이터의 대푯값 : 평균값-최빈값-중앙값
데이터의 전체적인 경향을 파악하기 위해 평균값이나 최빈값, 중앙값 같은 지표를 자주 사용합니다.
단, 이러한 지표는 그 데이터를 집약한대푯값이며, 데이터 자체를 나타내는 것은 아닙니다. 대푯값은 매우 편리한 지표이지만 자칫하면 잘못된 해석을 불러올 수 있습니다. 대푯값을 제대로 사용하려면 대푯값의 성질을 올바로 이애해야 합니다. 데이터를 대푯값만으로 판다하기보단, 실제 데이터의 분포를 관찰해서 데이터의 특징을 간파해야 합니다.
데이터의 분포를 확인한다.
데이터의 분포를 확인할 때 히스토그램을 사용합니다.
"17세의 신장 분포(히스토그램)"
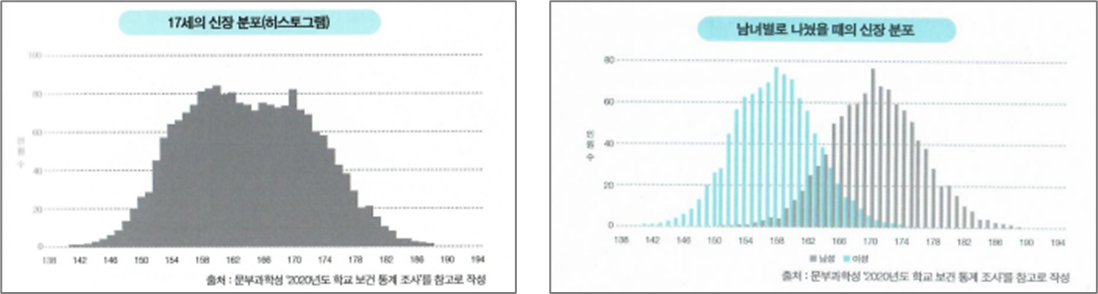
분포를 보면 중앙에 움푹한 부분이 있습니다. 이러한 분포를 봤을 때 '왜 데이터에 움푹한 곳이 있을까?'하며 데이터의 움푹한 곳이 있는 밴경에 관해 생각합니다. 이 사례에서는 '17세 키니까 남녀 차이가 있는게 아닐까?'라는 가설을 세워볼 수 있습니다. 남녀별로 색깔을 나눠보면 다음 그림과 같습니다. 남성이 여성보다 키가 더 큰 경향이 있는 것 같습니다.
복수의 분포가 합쳐져 하나의 분포가 된 사례도 있기 때문에 데이터가 발생한 배경이나 관측된 배경을 의식하면서 데이터를 마주해야 합니다.
실제 사회에서는 평균값=최빈값이 아닌 경우가 많다.
평균값이 최반값이 일치하지 않는 두 가지 예시
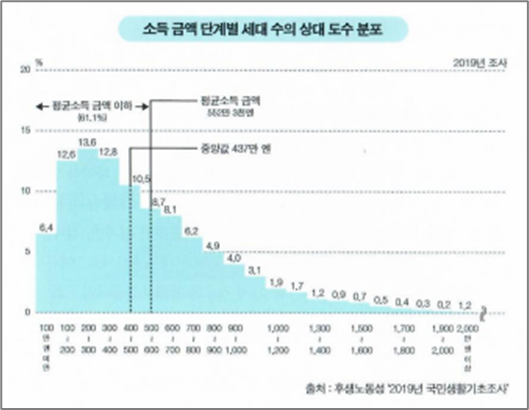
일본 국민의 대부분은 552만 3천 엔의 소득이 있다?
(평균소득 552만3천 엔, 평균소득 금액 이하 61.1%, 중앙값 437만 엔)
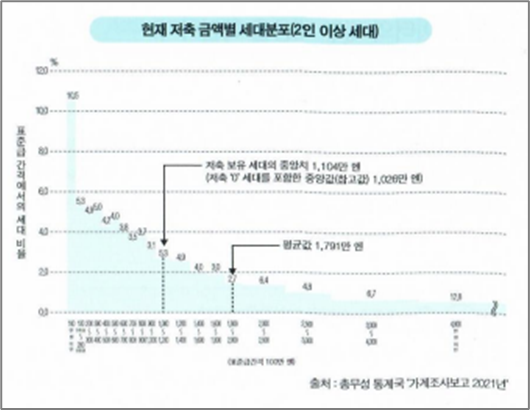
대부분의 세대는 1,791만 엔을 저축해 놓았다?
(평균값 1,791만 엔, 저축 보유 세대의 중앙값 1,104만 엔, 저축 '0'세대를 포함한 중앙값(참고값) 1,026만 엔
2-3 데이터의 세부 내용을 확인하자!
이상값이 있는 데이터를 다루는 경우, 이상값을 적절하게 수정(혹은 제외)하고 분석합니다.
데이터가 존재하지 않는 것을 '결측'이라고 합니다. 어떤 조건으로 데이터 취득이 끝난 데이터를 '중도절단 데이터'라고 합니다. 결측값과 중도절단 유무를 확인함과 동시에 배경을 생각하면서 데이터를 파악합니다.
2-4 데이터의 관계성을 파악하자!
두 데이터의 관계성을 확인할 때 산포도를 자주 사용합니다. 한쪽 데이터가 크면 다른 한쪽 데이터도 큰 관계성을 보입니다. 이와 같은 관계를 '상관관계'라고 합니다.
'상관관계' 가운데서도 한쪽이 원인이고, 다른 한쪽이 결과인 관계를 '인과관계'라고 합니다. 그런데 상관관계가 있으면 모두 인과관계가 되느냐하면 그렇지는 않습니다. 겉보기에 상관관계가 있는 듯 보이지만, 두 데이터 사이에 인과관계가 없는 것을 '허위상관'이라고 합니다.
상관관계에는 '양의 상관'과 '음의 상관'이 있습니다. 상관의 정도를 나타내는 지표로 '상관계수'가 있습니다. 상관계수는 -1~1까지의 값을 취합니다. 일반적으로 상관계수가 0.7 이상이면 강한 양의 상관이 있다고 말합니다. 또, 상관계수가 -0.7이하면 강한 음의 상관이 있다고 말합니다.
단, 상관계수는 어디까지나 상관의 정도를 나타내는 지표일 뿐입니다. 평균값만으로 데이터 분포를 파악할 수 없듯, 상관계수만 보고 두 데이터의 관계성을 파악할 수는 없습니다. 상관계수를 확인하면서도 산포도를 이용해 데이
터의 치우침이나 흩어진 정도를 확인합니다.
[ 제3장 데이터를 설명하는 힘을 기른다 ]
목적에 맞는 그래프 표현을 골라 설득력 있는 보고서나 제안서를 작성합니다. 비즈니스 현장에서는 상사에게 보고하거나 고객에게 제안할 때 데이터를 이용해서 논리적으로 설명해야 합니다. 최근에는 데이터에 기반한 의사 결정이 중요시되고 있으며, 데이터를 적절하게 가시화하는 힘의 필요성이 높아지고 있습니다.
그래프를 작성할 때는 읽는 사람에게 오해를 불러일으키는 그래프를 만들지 않도록 주의해야 합니다.
데이터를 비교함으로써 대상이 되는 사실이나 현상의 우열, 간격을 확인합니다.
그래프의 특이점이나 경향성, 상이성이나 관련성에 주목해서 데이터에서 과제를 찾아냅니다.
데이터를 시가화함으로서 입수한 데이터의 특징과 상이점, 관련성을 찾아내며, 그 결과를 업무에 활용합니다.
설명하려는 내용에 따라 선택해야 할 그래플 표현 방식이 다릅니다.
1) 막대 그래프 : 수치 데이터의 항목 간 차이를 표현
(각 항목의 값을 비교 - 각 항목 값의 차이를 확인 - 각 항목의 순위를 확인)
2) 꺽은선 그래프 : 시계열 데이터의 시간적 변화를 표현
(데이터의 시간적 변화를 확인 - 트렌드, 주기성을 확인 - 변곡점을 확인)
3) 산포도 : 수치 데이터의 항목 간 관계성을 표현
(2개의 항목에 상관관계가 있는지 확인 - 데이터의 치우침이나 흩어진 경향을 확인)
극단적으로 큰 값이 있다면 상이값을 제외하고 산포도를 작성합니다. 이때 상이값을 제외한 이유를 주석으로 기재합니다.
4) 원 그래프 : 수치 데이터의 구성을 표현
(각 항목이 전체에서 차지하는 비율을 확인 - 전체 내역을 확인)
3-1 데이터를 시각해보자!
데이터를 시가화함으로서 입수한 데이터의 특징과 상이점, 관련성을 찾아내며, 그 결과를 업무에 활용합니다.
적절한 그래프 표현
설명하려는 내용에 따라 선택해야 할 그래플 표현 방식이 다릅니다.
1) 막대 그래프 : 수치 데이터의 항목 간 차이를 표현
(각 항목의 값을 비교 - 각 항목 값의 차이를 확인 - 각 항목의 순위를 확인)
2) 꺽은선 그래프 : 시계열 데이터의 시간적 변화를 표현
(데이터의 시간적 변화를 확인 - 트렌드, 주기성을 확인 - 변곡점을 확인)
3) 산포도 : 수치 데이터의 항목 간 관계성을 표현
(2개의 항목에 상관관계가 있는지 확인 - 데이터의 치우침이나 흩어진 경향을 확인)
극단적으로 큰 값이 있다면 상이값을 제외하고 산포도를 작성합니다. 이때 상이값을 제외한 이유를 주석으로 기재합니다.
4) 원 그래프 : 수치 데이터의 구성을 표현
(각 항목이 전체에서 차지하는 비율을 확인 - 전체 내역을 확인)
비즈니스 현장에서는 원 그래프를 자주 사용하지만 과학기술 분야에서는 원 그래프 사용을 그리 권장하지 않습니다. 원 그래프는 각도를 나눠서 각 항목의 비율을 표현합니다. 원 그래프로 표현하는 항목 수가 많아지면 직감적으로 각도의 크기를 인식하기 어려워지기 때문에 비율을 올바르게 파악하지 못하게 됩니다. 또, 3D 원 그래프라면 비율을 파악하기가 더욱 어려워지기 때문에 데이터를 읽는 사람이 오해할 수 있습니다.
하지만 원 그래프가 전혀 사용되지 않는 건 아닙니다. 표시하는 항목 수가 2~3개 정도면 원 그래프를 사용해도 좋습니다.
3-2 데이터를 비교한다는 것은?
데이터를 비교함으로써 대상이 되는 사실이나 현상의 우열이나 간격, 계획값에 대한 달성 상황을 확인합니다.
적절한 비교 대상 설정
데이터를 비교할 때는 같은 성질을 가진 것끼리 비교하도록 비교 대상을 설정해야 합니다. 이를 'Apple to Apple 비교'라 합니다. 같은 성질을 가지는 사과끼리 비교하는 상황에서 유래했으며, 동일한 조건 간 비교를 의미합니다. 서로 다른 성질을 비교하는 것을 'Apple to Orange 비교'라 합니다. 사과와 오렌지처럼 성질이 다른 것을 비교해봤자 의미가 없다는 뜻입니다.
데이터를 비교하는 4가지 시점
1) 시점 1 : 어떤 시점과의 비교 : 기준이 되는 시점으로부터의 변화(변화율, 성장률)를 확인
2) 시점 2 : 계획값과의 비교 : 계획값에 대한 실적 달성 정도(달성률)를 확인
3) 시점 3 : 성질이 같은 것끼리의 차이 : 성질이 같은 것끼리의 차이(우열, 간격)를 확인
4) 시점 4 : 전체 대비 구성비(공헌도, 영향도, 점유율)를 확인
소매업에서는 매출 데이터를 분석할 때 매출을 고객 수와 고객 단가로 분해해서 생각합니다. 나눠서 생각함으로써 매출을 늘리기 위한 방법을 구체적으로 검토할 수 있습니다. 고객 수가 적으면 전단 배부나 포인트 제도 도입 등 방문을 촉진하는 방법을 검토합니다. 고객 단가가 낮다면 업셀링(Updelling, 고객이 구매하는 상품이나 서비스를 업그레이드하거나 추가 서비스를 포함하도록 유도하는 것)이나 크로스셀링(Cross-selling, 고객이 이미 구매했거나 구매 의사가 있는 상품 및 서비스와 다른 상품을 제안하여 관련 상품 구매를 유도하는 것) 등 1회당 구입 금액을 늘리는 방법을 검토합니다.
이처럼 숫자를 분해해서 비교함으로써 적절한 전략을 생각할 수있습니다. '이 숫자를 분해할 수 없을까?'를 생각하며 데이터를 대합니다.
곱셈에 의한 분해
숫자를 곱셈으로 분해하는 패턴입니다. 예를 들어 매출은 고객 수 X 고객 단가로 분해할 수 있습니다. 또, 고객 단가는 상품 단가 X 구입 개수로 분해할 수 있습니다. 이처럼 숫자를 곱셈으로 분해해서 각 숫자를 늘리기 위한 방법을 검토합니다.
덧셈에 의한 분해
숫자를 덧셈으로 분해하는 패턴입니다. 예를 들어 고객 수는 신규 고객 수 + 기존 고객 수로 분해할 수 있습니다. 또, 기존 고객 수는 활동 고객 수 + 휴면 고객 수로 분해할 수 있습니다.
3-3 데이터에서 과제를 찾아낸다!
데이터를 시각화해서 비교함으로써 과제를 찾아내어 해결책을 검토합니다.
데이터에서 과제를 찾아내는 순서
순서 1 : 데이터 집계값을 확인하자
순서 2 : 데이터를 시각화하고, 특이점이나 경향성, 상이성을 찾자
- 그래프를 파악할 때 값이 특이한 데이터는 없는지(특이점), 반복해서 보이는 경향은 없는지(경향성), 다른 값과 비교했을 때 다른 부분이 있는지(상이성)을 확인합니다.
순서 3 : 복수의 데이터를 조합해 관련성을 찾자
- 복수의 데이터를 조합해서 분석함으로써 단독 데이터만으로는 보이지 않았던 통찰을 얻을 수 있습니다.
순서 4 : 데이터에서 얻은 내용을 정리해 해결 방안을 검토하자
[ 제4장 데이터를 분류하는 힘을 기른다 ]
특징이 비슷한 데이터를 그룹으로 모아 대량의 데이터에서 중요한 요점을 뽑아냅니다.
데이터를 분류할 때 반드시 처음에 데이터를 분류하는 목적을 명확하게 합니다.
주로 k-means 법을 이용해 대량의 데이터를 분류합니다. K-means법을 이용할 때는 초깃값을 바꿔가며 여러 차례 분류함으로써 극단적인 분류 결과가 나오지 않았는지 확인하도록 합시다.
4-1 특징이 비슷한 데이터를 그룹으로 만들자!
대량의 데이터를 몇 개의 그룹으로 나눠서 그룹별 특징과 해결 방안을 고찰합니다.
데이터를 그룹으로 나누는 의미
대량의 데이터를 몇 개의 그룹으로 나눠 생각하면 데이터를 파악, 비교하기 쉬어지기 때문입니다. 특징이 비슷한 데이터끼리 모아서 그룹을 만드는 것이 매우 중요합니다. 특징이 비슷한 데이터를 그룹으로 모음으로써 대량의 데이터 안에서 필요한 것을 찾아내기 쉽게 만듭니다.
그룹별 해결 방안을 생각한다
데이터를 그룹으로 나누면 데이터에 바탕을 둔 해결 방안을 생각하기 쉬워집니다.
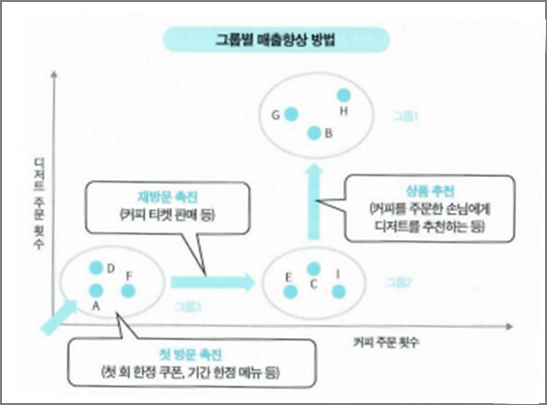
데이터의 특징이 비슷하다는 판단
데이터의 거리가 가까우면 '비슷하다', 멀면 '비슷하지 않다'고 판단을 내립니다. 거리가 가깝다는 확신을 얻기 위해 '거리 공식(피타고라스의 정리)'에 대입해 계산해봅니다. 가로 길이와 세로 길이를 알면 거리 공식을 이용해 거리를 계산할 수 있습니다.
이처럼 스케일이 다른 두 가지 지표(책 예시 : 체중, 키)를 사용해 거리를 계산하면 차이가 큰 지표 (여기서는 체중)의 영향이 강하게 드러나서, 차이가 작은 다른 하나의 지표(여기서는 키)는 거리로 반영되기 어려워집니다. 이 문제를 해결하기 위해 '데이터 표준화(평균값을 0, 분산을 1로 만드는 처리)를 해서 각 지표를 똑같이 다루도록 변환합니다.
산포도를 확인할 때도 세록축과 가로축에 스케일이 다른 데이터가 배치되지 않았는지 확인하도록 합시다.
4-2 목적에 맞게 데이터를 분류하자!
데이터를 분류하는 목적을 명확하게 정한 뒤, 그 목적에 따라 특징이 비슷한 데이터는 같은 그룹으로 분류하고, 반대로 특징이 비슷하지 않은 데이터는 다른 그룹으로 분류합니다.
데이터 분류의 어려움
어떤 관점에서 그룹을 나누느냐에 따라 분류 결과가 달라지기 때문에 '이 데이터는 이렇게 분류하면 정답'이라고 명확하게 정의할 수 없습니다. 데이터를 분류할 때는 사전에 데이터를 분류하는 목적을 확실하게 정해두는 것이 중요합니다. 데이터를 그룹으로 나눠달라는 의뢰를 받으면 먼저 반드시 분류 목적을 확인합니다. 데이터를 분류하는 목적이 확실하지 않으면 어떤 관점에서 데이터를 그룹으로 나눠야 하는지를 결정할 수 없기 때문입니다. 데이터를 분류할 때는 사전에 데이터를 분류하는 목적을 명확하게 하고, 그 목적에 따라 데이터를 모으는 일이 중요합니다. 또, 같은 데이터를 사용한다고 하더라도 어떠한 관점에서 분류하느냐에 따라 분류 결과가 달라진다는 사실을 이해해둡시다.
4-3 데이터를 기계적으로 분류하자!
기계적으로 데이터를 분류할 수 있으면 수십만 건이 나 수백만 건의 데이터라 하더라도 데이터를 그룹으로 나눌 수 있습니다.
데이터를 분류하는 방법 : k-means법
데이터 과학자가 자주 사용하는 k-means법에서는 우선 데이터를 몇 개의 그룹으로 분류할지를 결정해야 합니다. 데이터를 몇 개의 그룹으로 나눌지를 정하면 누구든 상관없으니 일단 그룹의 중심이 되는 사람(이를 k-means법에서는 '초깃값'이라 부릅니다)을 무작위로 고릅니다. 초깃값을 정하고 나면, 여러 번 거리 계산을 반복해서 기계적으로 데이터를 분류할 수 있습니다. K-means법을 이용하면 데이터가 수천 건 혹은 수만 건이 되어도 기계적으로 데이터를 분류할 수 있습니다.
K-means법은 매우 편리한 분류 방법이지만, 한 가지 주의해야 할 점이 있습니다. 초깃값을 고르는 방법에 따라서 k-means법에 의한 분류 결과가 달라지는 경우가 있다는 사실입니다. 데이터의 분포 상황에 따라 k-means법에 의한 분류 결과가 하나로 정해지지 않고, 초깃값을 선택하는 방법에 따라 속하는 그룹이 크게 달라집니다. 이 현상은 'k-means법의 초깃값 문제'로 널리 알려져 있으며, 한 번의 k-means법에 의한 분류 결과만을 보고 판단할 것이 아니라, 몇 번의 초깃값을 바꿔가면서 k-means법을 시행함으로써 극단적인 분류 결과가 나오지 않았는지 확인합니다.
4-4 데이터 분류를 체험하자!
순서1 : 데이터를 분류하는 목적을 명확하게 하자
순서2 : 데이터를 분류하기 위한 관점을 정리하자
- 몇 개의 그룹으로 나눌 수 있는지도 분명하지 않은 경우는 데이터에 색깔을 칠해서 데이터의 특징을 확인합니다. 이를 히트 맵(heat map)이라고 부르며 엑셀에서는 '조건부 서식'을 활용해서 간단히 색을 칠할 수 있습니다.
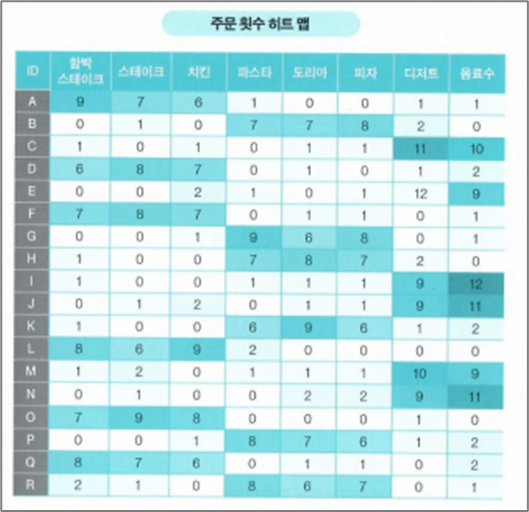
순서3 : 데이터를 그룹으로 나누자
순서4 : 그룹에 이름을 붙이고 방안을 검토하자
- 각 그룹의 이름은 해당 그룹의 특징을 나타내는 이름으로 지을 것을 추천합니다. 그룹의 특징을 잘 표현한 이름을 붙여두면 이후 해결 방안 검토나 업무 진행 시 편해지기 때문입니다.
[ 제5장 데이터에서 법칙을 발견하는 힘을 기른다 ]
데이터에서 법칙을 찾아내 그 법칙을 적용함으로서 판별 문제의 결과를 추측합니다.
데이터 근거를 바탕으로 관련 문제의 결과를 추측하기 위해 의사결정 트리 모델을 활용합니다.
판별 문제의 정밀도를 정답률, 적합률, 재현율 같은 지표를 이용해 평가합니다.
판별 문제의 추측 결과를 확인할 때는 추측 결과가 잘못될 때도 있다는 사실을 알아두어야 합니다.
5-1 데이터에서 법칙을 발견한다!
데이터에서 법칙을 찾아내 그 법칙을 적용함으로써 과제 해결이나 방법 제정으로 연결합니다.
데이터 과학자는 '왜'라는 물음이 직감과 맞는지를 생각하면서 데이터를 확인합니다.
판별 문제(AB 테스트)의 특징은 둘 중 한쪽 값을 반드시 추측해야 한다는 점입니다. 당연히 추측이 틀리는 경우도 있기 때문에 판별 문제의 결과를 어떻게 해석하는지 결과 확인 방법을 제대로 배워두어야 합니다. 데이터가 적으면 어느 쪽이 될지 자신 있게 추측할 수 없습니다. 따라서, 판별 문제를 생각할 때는 법칙을 끌어내기 위한 데이터를 많이 모아야 합니다.
5-2 판별 문제를 푸는 의사결정 트리 모델
의사결정 트리 모델은 판별 문제를 풀기 위한 수법 중 하나로 복수의 조건 갈래를 나무 구조로 표현해 직감적으로 이해하기 쉬운 모델이라 알려져 있습니다.
의사결정 트리 모델을 성장시킨다
의사결정 트리 모델은 조건 가지치기를 여러 차례 반복하면서 나무를 성장시킬 수 있습니다.
5-3 판별 문제의 정밀도를 평가해보자!
판별 문제에서는 '생존/사망'처럼 반드시 어느 하나의 값을 추측합니다. 만약 결과를 아는 데이터를 준비할 수 있으면 추측한 값이 '정답'이었는지 '오답'이었는지를 확인할 수 있습니다. 정답 및 오답 결과를 바탕으로 판단 문제 추측 시 옳고 그름(정밀도) 여부를 평가합니다.
2 X 2칸 크로스 표로 정리한다
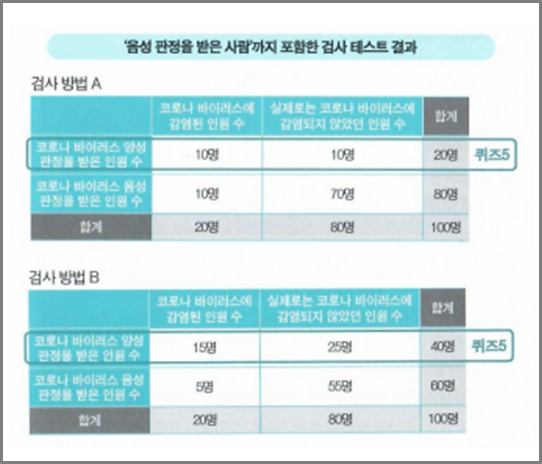
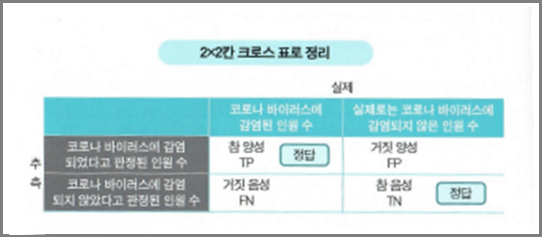
각가의 평가를 산출하기 위해 2X2칸 크로스 표로 판별 문제의 추측 결과를 정리합니다.
4칸은 저마다 이름이 있습니다. 왼쪽 위가 '참 양성(TP : True Positive)', 오른쪽 위가 '거짓 양성(FP : False Positive)', 왼쪽 아래가 '거짓 음성(FN : False Negative)', 오른쪽 아래가 '참 음성(TN : True Negative)'입니다.
판별 문제의 정밀도를 평가하는 방법
판별 문제의 정밀도를 평가하기 세 가지 지표를 활용합니다. 앞선 2X2칸 크로스 표 의 값을 바탕으로 평가합니다.
1) 정답률 : 전체 가운데 올바르게 판단(정답)한 비율을 가리킵니다.
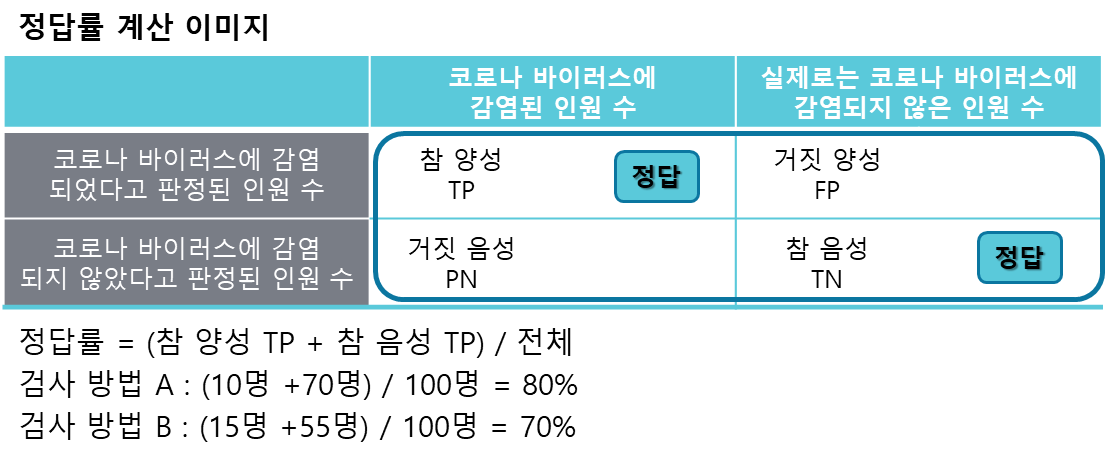
2) 적합률 : 양성 혹은 음성이라고 판정한 가운데 정답을 맞힌 비율을 가리킵니다. 적합률을 계산할 때는 2X2칸 크로스 표를 가로로 봅니다. 감염되었다고 판정된 경우와 감염되지 않았다고 판정된 두 경우로 적합률을 계산할 수 있습니다. 일반적으로 감염되었다고 판정된 경우의 '양성 적합률'만을 계산할 때가 많습니다.
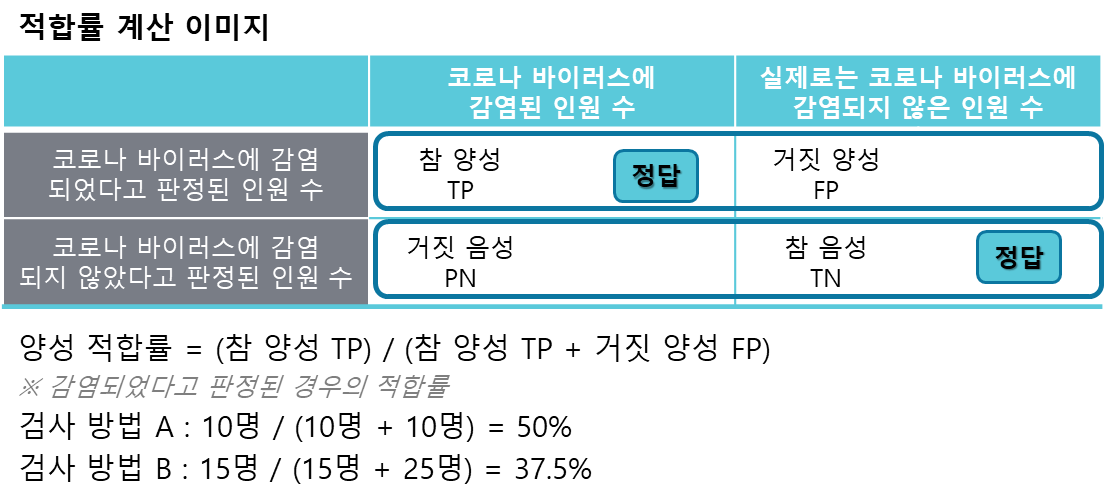
3) 재현율 : 실제로 양성 혹은 음성이었던 값의 정답을 맞힌 비율을 가리킵니다. 재현율을 계산할 때는 2X2칸 크로스 표를 세로로 봅니다. 실제로 코로나 바이러스에 감염된 사람 가운데 올바로 판정한 비율을 확인하기 위한 지표입니다. 적합률과 마찬가지로 실제로 코로나 바이러스에 감염되지 않았던 경우의 재현율을 계산할 수 있습니다. 많은 경우, 실제로 코로나 바이러스에 감염되었단 사람을 올바로 판정했는지에 관심이 있기 때문입니다.
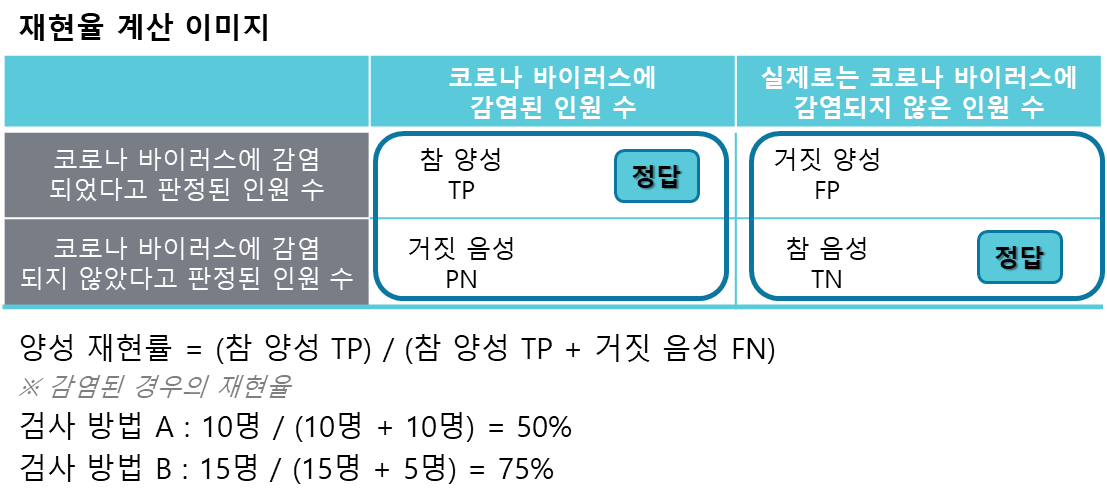
적합률과 재현율 가운데 어느 쪽이 중요할까?
많은 경우, '적합률'과 '재현율'은 트레이드 오프(trade-off) 관계에 있습니다. 즉, 적합률을 올리고자 하면 재현율을 낮아지고, 재현율을 올리고자 하면 적합률이 낮아지는 관계에 있다는 의미입니다.
검사 방법 B는 과잉 반응하기 때문에 감염된 사람을 적게 놓치고 있습니다(재현율이 높다). 그런데 검사 방법 B는 놓치는 비율은 적었지만, 잘못해서 코로나 바이러스에 감염되었다고 판정하는 오(誤)검지가 많습니다 (적합률이 낮다). 한편 검사 방법 A는 오검지가 적었지만, 감염된 사람을 놓치는 경우도 많았습니다.
오검지를 낮추고 싶다면 '적합률'로, 놓치는 부분을 낮추고 싶다면 '재현율'로 평가하면 됩니다.
5-4 의사결정 트리 모델을 활용해보자!
순서 1 : 데이터 항목을 확인하고, 대략적인 가설을 세워보자
순서 2 : 데이터를 관찰하고 비정형 데이터가 없는지 확인하자
순서 3 : 데이터에서 법칙을 찾아내자
순서 4 : 데이터에서 찾은 법칙에 적응해 추측하자
[ 제6장 데이터를 보고 예측하는 힘을 기른다 ]
수식 데이터의 관계성을 찾아내, 미지의 숫자를 예측합니다.
수치 데이터의 관계성을 찾아낼 때, '데이터의 치우침'과 '데이터의 수'에 주의를 기울입니다.
시계열 데이터에 포함되는 '트렌드'나 '주기성'을 고려하면서 미래의 수치를 예측합니다.
6-1 수치 데이터의 관계성을 확인하자!
주어진 숫자 안에서 관계성을 찾아내고, 찾아낸 관계성을 적용함으로써 미지의 수치를 예측합니다.
6-2 내삽과 외삽에 주의하자!
데이터를 보고 찾아낸 관계성을 적용할 수 있는 경우와 적용할 수 없는 경우
수치 데이터에서 찾아낸 관계성을 적용할 수 있는 경우와 적용할 수 없는 경우가 있습니다.
미지의 데이터가 이미 알고 있는 데이터 사이에 있는 경우, 이미 알고 있는 데이터에 둘러싸인 안쪽을 향해 미지의 데이터를 예측하게 됩니다. 이 안쪽을 향해 예측하는 것을 '내삽(Interpolation, 보간(補間)'이라고 부르며, 많은 경우 데이터에서 찾아낸 관계성을 적용함으로써 그럴듯한 예측을 할 수 있습니다.
미지의 데이터가 이미 알고 있는 데이터의 바깥쪽에 있을 때, 이미 알고 있는 데이터로부터 바깥쪽을 향해 미지의 데이터를 예측하게 됩니다. 이를 '외삽(Extrapolation, 보외(補外)'이라고 부르며, 이럴 경우 데이터에서 찾아낸 관계성을 적용해도 그럴듯한 예측은 어렵다고 알려져 있습니다.
외삽으로 예측했을 때, 실제로는 말도 안 되는 예측 결과가 나오는 경우가 흔히 있습니다.
6-3 데이터의 치우침에 주의하자!
수치 데이터에서 발견한 관계성을 적용할 때 '내삽'외삽'외에도 또 한가지 주의할 점이 있습니다. 관계성을 찾아내기 위해 사용한 데이터의 치우침에 주의하는 것입니다. 수치 데이터의 관계성을 확인할 때 데이터의 치우침이 없는지 항상 확인합니다. 치우친 데이터에서 찾아낸 관계성은 적용할 수 있는 범위가 제한적일 때가 있기 때문이지요,
데이터의 치우침이 없는지 확인하다
'휴일 매출은 평일 매출의 절반 정도'라는 관계성의 배후에는 '오피스 빌딩 안에 있는 점포가 많다'는 데이터의 치우침이 있었습니다. 따라서, 이 관계성은 오피스 빌딩에 있는 점포에는 적용되지만, 상업 시설이나 주택 단지에 있는 점포에 그대로 적용할 수 없습니다.
데이터의 관계성을 확인할 때는 그 관계성의 배후에 데이터의 치우침이 없는지 주의할 필요가 있습니다. 만약 데이터에 치우침이 있을 때는 관계성을 적용할 수 있는 범위에 제한이 생길 가능성이 있다는 사실을 알아두어야 합니다.
식표품점의 캠페인 실패
스마트폰 앱을 사용해서 앙케트를 실시하기로 하였습니다. 스마트폰 앱을 통해 앙케트 데이터를 모으면 종이 앙케트에 기재한 내용을 다시 입력해야 하는 번거로움도 없으니 괜찮은 아이디어라고 생각했습니다. 앙케트에서는 '휴일에 기분을 내고 싶을 때 어떤 음식을 먹고 싶나요?'라는 질문을 하기로 했습니다. 앙케트를 실시한 결과 300명의 회원이 응답했고, 성별 연령대, 먹고 싶은 음식 종류와 자유로운 의견을 받았습니다.
'행복한 고기의 날'이라는 이름을 내걸고 대대적으로 홍보했습니다. 그런데 막상 당일이 되어도 손님들 반응이 영 신통치 않아서 들어온 상품 일부를 다음 날 할인 판매하게 되었지요.
캠패인이 끝난 뒤 점장은 이번 캠페인이 실패한 원인이 궁금해졌습니다.
스마트폰 앱 회원은 젊은 회원층이 중심으로, 고령층 손님은 거의 사용하지 않습니다. 앙케트를 통해 모은 '고기 종류를 원하는 사람이 많다'는 결과는 마트를 방문하는 손님의 연령 구성을 반영하지 않고, 일부 젊은 층의 결과만을 추출했던 것입니다. 때문에 '행복한 고기의 날 세일'은 실패로 끝나고 말았습니다.
이처럼 데이터의 관계성을 확인할 때는 어쩌면 입수한 데이터에 치우침이 있을지도 모른다는 마음을 먼저 가져보면 좋습니다. 데이터의 치우침에 현혹되지 않으려면 데이터에서 찾아낸 관계성을 상식이나 도메인 지식에 비춰보고, 조금이라도 위하감이 있으면 확인하는 습관을 들여야 합니다.
데이터의 관계성을 확인할 대는 데이터의 치우침뿐 아니라, 데이터 수에도 주위해야 합니다. 특히 데이터의 수가 지나치게 적은 경우, 데이터에서 찾아낸 관계성은 거의 쓸모가 없습니다.
6-4 시간 변화에 주목하자!
시계열 데이터에는 같은 주기로 변화를 반복하는 '주기성'이 포함되어 있을 때가 많습니다.
시계열 데이터의 세세한 변동을 제외한 데이터의 경향을 '트렌드'라 부릅니다. 대다수의 시계열 데이터에는 앞서 살펴본 '주기성'과 '트렌드'가 포함되어 있고, 이를 가미해서 분석을 진행해야 합니다.
시계열 데이터에서는 다양한 변동을 발견할 수 있다
시계열의 데이터의 주기성은 시간대별 변동만이 아닙니다. 계절 변동이나 요일 변동 등 시계열 데이터에서는 다양한 변동(주기성)을 찾을 수 있습니다.
시계열 데이터에 포함된 '트렌드'와 '주기성'을 고려해서 미래의 수치를 예측합니다.
6-5 데이터를 보고 예측하자!
순서 1 : 데이터를 확인하고, 대략적인 가설을 세워보자
순서 2 : 데이터를 관찰하고, 비정형(상이값과 이상값) 데이터가 없는지 확인하자
순서 3 : 수치 데이터의 관계성을 찾아내자
- 수치 데이터의 관계를 확인할 때 산포도를 활용합니다.
순서 4 : 수치 데이터에서 찾아낸 관계성을 적용해 예측하자

'데이터 분석 (with Rstudio)' 카테고리의 다른 글
| [Rstudio] 대한민국 지도 그리기 (전국 지도, 지역별 지도) (0) | 2024.04.18 |
|---|---|
| [Rstudio] 대한민국 지도 그리기 (전국 지도) (0) | 2024.04.16 |
| [Rstudio] 세계지도 그리기와 색칠하기 (전체, 국가별 지도) (0) | 2024.04.15 |
| [Rstudio] 의회 다이어그램 with 국회의원 선거 의석 수 결과 (0) | 2024.04.12 |
| [Rstudio] 루프(Loop) 반복문 - for 루프 문과 while 루프 문 (1) | 2024.03.26 |



